
简介
MobileNetV2 是由谷歌团队于 2018 年提出的一种轻量级卷积神经网络模型,是 MobileNetV1 的改进版本,旨在在保持准确性的前提下,极大地减少模型的参数数量和计算复杂度,从而适用于移动设备和嵌入式系统等资源受限的场景。
为什么使用MobileNetV2模型?
-
轻量级模型,运行速度快
-
在ImageNet数据集上预训练,识别准确度高
-
适合移动设备和普通电脑使用
目标
使用 python 和深度学习框架,利用 MobileNetV2 模型,完成猫图像的识别;最后完成网页端部署。
实现
环境配置
推荐虚拟环境
virtualenv venv
.\venv\Scripts\activate创建 requirements.txt, pip install -r requirements.txt 安装相关依赖
tensorflow>=2.8.0
opencv-python>=4.5.5
numpy>=1.21.0
pillow>=8.3.0 主程序编写
调包
import tensorflow as tf
import cv2
import numpy as np
from PIL import Image
import os-
tensorflow: 用于加载和使用预训练模型
-
cv2: 用于图像处理
-
numpy: 用于数组操作
-
PIL: 用于图像加载和预处理
创建加载模型函数
def load_model():
"""
加载预训练的MobileNetV2模型
Returns:
model: 加载好的MobileNetV2模型
"""
print("开始加载模型...")
# 使用ImageNet预训练的MobileNetV2模型
model = tf.keras.applications.MobileNetV2(weights='imagenet')
#虽然ImageNet数据集本身不专门针对猫的识别,但其预训练的特征可以很好地迁移到猫狗分类等任务中
return model创建图像预处理函数
def preprocess_image(image_path):
"""
预处理图片,使其符合模型输入要求
Args:
image_path: 图片文件路径
Returns:
processed_image: 预处理后的图片数组,形状为(1, 224, 224, 3)
"""
print("开始预处理图片...")
# 打开图片
img = Image.open(image_path)
print("图片打开成功")
# 调整图片大小为224x224,这是MobileNetV2的标准输入大小
img = img.resize((224, 224))
print("图片调整大小完成")
# 转换为numpy数组
img_array = np.array(img)
print("转换为numpy数组完成")
# 应用MobileNetV2的预处理,包括归一化和通道调整
img_array = tf.keras.applications.mobilenet_v2.preprocess_input(img_array)
print("预处理完成")
# 添加批次维度,因为模型需要批量输入
return np.expand_dims(img_array, axis=0)创建猫检测函数
def detect_cat(image_path, model, confidence_threshold=0.5):
"""
检测图片中是否有猫
Args:
image_path: 图片文件路径
model: 预训练的MobileNetV2模型
confidence_threshold: 置信度阈值,默认0.5
Returns:
tuple: (是否检测到猫, 检测结果描述)
"""
print(f"开始检测 {image_path}")
# 预处理图片
processed_image = preprocess_image(image_path)
# 使用模型进行预测
predictions = model.predict(processed_image)
# 解码预测结果,获取top5的预测类别
decoded_predictions = tf.keras.applications.mobilenet_v2.decode_predictions(predictions, top=5)[0]
print("解码预测结果完成\n\n")
# 定义猫的标签,这些是ImageNet数据集中猫的类别
cat_labels = ['tabby', 'tiger_cat', 'Persian_cat', 'Siamese_cat', 'Egyptian_cat']
# 检查预测结果中是否包含猫,并且置信度超过阈值
for _, label, prob in decoded_predictions:
if any(cat in label for cat in cat_labels) and prob >= confidence_threshold:
return True, f"检测到猫 ({label}, 置信度: {prob:.2f}) \n\n"
return False, "未检测到猫\n\n" 实现主函数
在实现主函数前,我创建了两个函数来分别处理单个文件和多个文件
def detect_file(model, confidence=0.5):
image_path = input("请输入图片路径:")
print("\n\n")
try:
is_cat, result = detect_cat(image_path, model)
print(result)
except Exception as e:
print(f"错误: {str(e)}")
def detect_folder(model, confidence=0.5):
folder_path = input("请输入测试文件夹路径: ")
print("\n\n")
all_items = os.listdir(folder_path)
files = [folder_path+"\\"+ f for f in all_items if os.path.isfile(os.path.join(folder_path, f))]
for image_path in files:
try:
# 检测图片
is_cat, result = detect_cat(image_path, model)
print(result)
except Exception as e:
print(f"发生错误: {str(e)}")
def set_confidence():
#获取置信度阈值
try:
confidence = float(input("请输入置信度阈值(0-1之间,默认0.5): ") or 0.5)
if confidence < 0 or confidence > 1:
print("置信度必须在0-1之间,使用默认值0.5")
confidence = 0.5
except ValueError:
print("输入无效,使用默认值0.5")
confidence = 0.5
return confidence注:置信度阈值决定了模型预测结果的可接受最低置信水平,即判断模型是否可靠。
串起来上面的函数,实现主函数
def main():
"""
主函数,程序的入口点
"""
try:
# 加载模型
model = load_model()
print("模型加载完成")
except Exception as e:
print("模型加载失败\n",e)
confidence = set_confidence()
# detect_file(model)
detect_folder(model, confidence)测试
先拿一张猫猫的图片来测试

==》
开始加载模型...
2025-04-12 16:03:42.296507: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: SSE3 SSE4.1 SSE4.2 AVX AVX2 AVX512F AVX512_VNNI AVX512_BF16 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
模型加载完成
请输入置信度阈值(0-1之间,默认0.5):
请输入图片路径:test\cat2.png
开始检测 test\cat2.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 448ms/step
解码预测结果完成
检测到猫 (Egyptian_cat, 置信度: 0.74)
虽然检测出了猫,但是类别上非常错。
再检测一下人。

模型加载完成
请输入置信度阈值(0-1之间,默认0.5):
请输入图片路径:test\human.png
开始检测 test\human.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 436ms/step
解码预测结果完成
未检测到猫可以看出他基本特征还是能够提取的,再测试一组数据。
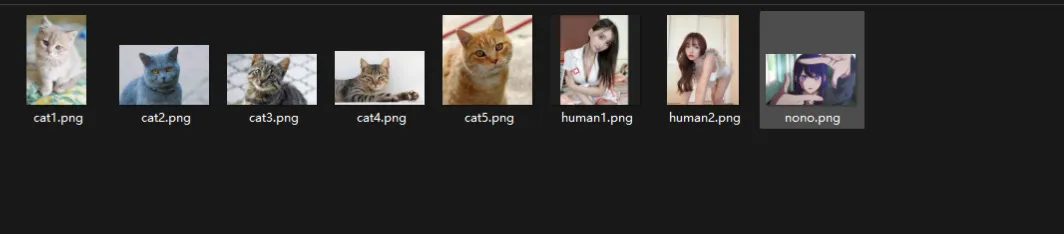
模型加载完成
请输入置信度阈值(0-1之间,默认0.5): 0.3
请输入测试文件夹路径: test
开始检测 test\cat1.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 447ms/step
解码预测结果完成
未检测到猫
开始检测 test\cat2.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 31ms/step
解码预测结果完成
检测到猫 (Egyptian_cat, 置信度: 0.74)
开始检测 test\cat3.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step
解码预测结果完成
未检测到猫
开始检测 test\cat4.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 35ms/step
解码预测结果完成
检测到猫 (tabby, 置信度: 0.58)
开始检测 test\cat5.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step
解码预测结果完成
检测到猫 (Egyptian_cat, 置信度: 0.33)
开始检测 test\human1.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step
解码预测结果完成
未检测到猫
开始检测 test\human2.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step
解码预测结果完成
未检测到猫
开始检测 test\nono.png
开始预处理图片...
图片打开成功
图片调整大小完成
转换为numpy数组完成
预处理完成
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step
解码预测结果完成
未检测到猫
预测效果,其实很差,但可以调整置信度。
微调和优化
概念介绍
- 模型微调(Fine-tuning):
-
定义: 在预训练模型的基础上,使用特定任务的数据进行再训练。
-
目的: 适应特定任务,提高模型在该任务上的表现。
-
方法: 冻结部分层,只训练特定层,或者在整个模型上进行微调。
- 模型优化:
-
定义: 通过调整模型结构、超参数等方式提高模型性能。
-
目的: 提高模型的准确性、速度和效率。
-
方法: 调整学习率、批次大小、使用正则化等。
实施:
- 数据准备
-
收集更多数据: 获取更多与任务相关的数据。
-
数据增强: 使用数据增强技术(如旋转、翻转、缩放)来增加数据多样性。
- 模型微调
-
冻结层: 冻结预训练模型的前几层,只训练后面的全连接层。
-
解冻层: 在初步训练后,解冻更多层进行微调。
这部分暂时不会,先留着。
网页开发
测试


用 cat2.png

识别效果不好,只能调低置信度,测试 cat5.png

只能先这样了。
最后简单美化一下前端。


主要代码如下
cat_detector.py
"""
猫识别程序
使用预训练的 模型来识别图片中是否包含猫
"""
import tensorflow as tf # 深度学习框架
import cv2 # 图像处理库
import numpy as np # 科学计算库
from PIL import Image # Python图像处理库
import os
#加载函数
def load_model():
"""
加载预训练的MobileNetV2模型
Returns:
model: 加载好的MobileNetV2模型
"""
print("开始加载模型...")
# 使用ImageNet预训练的MobileNetV2模型
model = tf.keras.applications.MobileNetV2(weights='imagenet')
return model
#图像预处理
def preprocess_image(image_path):
"""
预处理图片,使其符合模型输入要求
Args:
image_path: 图片文件路径
Returns:
processed_image: 预处理后的图片数组,形状为(1, 224, 224, 3)
"""
print("开始预处理图片...")
# 打开图片
img = Image.open(image_path)
print("图片打开成功")
# 调整图片大小为224x224,这是MobileNetV2的标准输入大小
img = img.resize((224, 224))
print("图片调整大小完成")
# 转换为numpy数组
img_array = np.array(img)
print("转换为numpy数组完成")
# 应用MobileNetV2的预处理,包括归一化和通道调整
img_array = tf.keras.applications.mobilenet_v2.preprocess_input(img_array)
print("预处理完成")
# 添加批次维度,因为模型需要批量输入
return np.expand_dims(img_array, axis=0)
#实现猫检测函数
def detect_cat(image, confidence_threshold=0.3):
model = tf.keras.applications.MobileNetV2(weights='imagenet')
processed_image = preprocess_image(image)
predictions = model.predict(processed_image)
decoded_predictions = tf.keras.applications.mobilenet_v2.decode_predictions(predictions, top=5)[0]
# 定义猫的标签
cat_labels = ['tabby', 'tiger_cat', 'Persian_cat', 'Siamese_cat', 'Egyptian_cat']
for _, label, prob in decoded_predictions:
if any(cat in label for cat in cat_labels) and prob >= confidence_threshold:
return f"检测到猫 ({label}, 置信度: {prob:.2f})"
return "未检测到猫"app.py
from flask import Flask, request, render_template
import cat_detector
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == "POST":
file = request.files['file']
if file:
result = cat_detector.detect_cat(file)
return render_template('result.html', result=result)
return render_template('upload.html')
if __name__ == "__main__":
app.run(debug=True)前端就不说了。
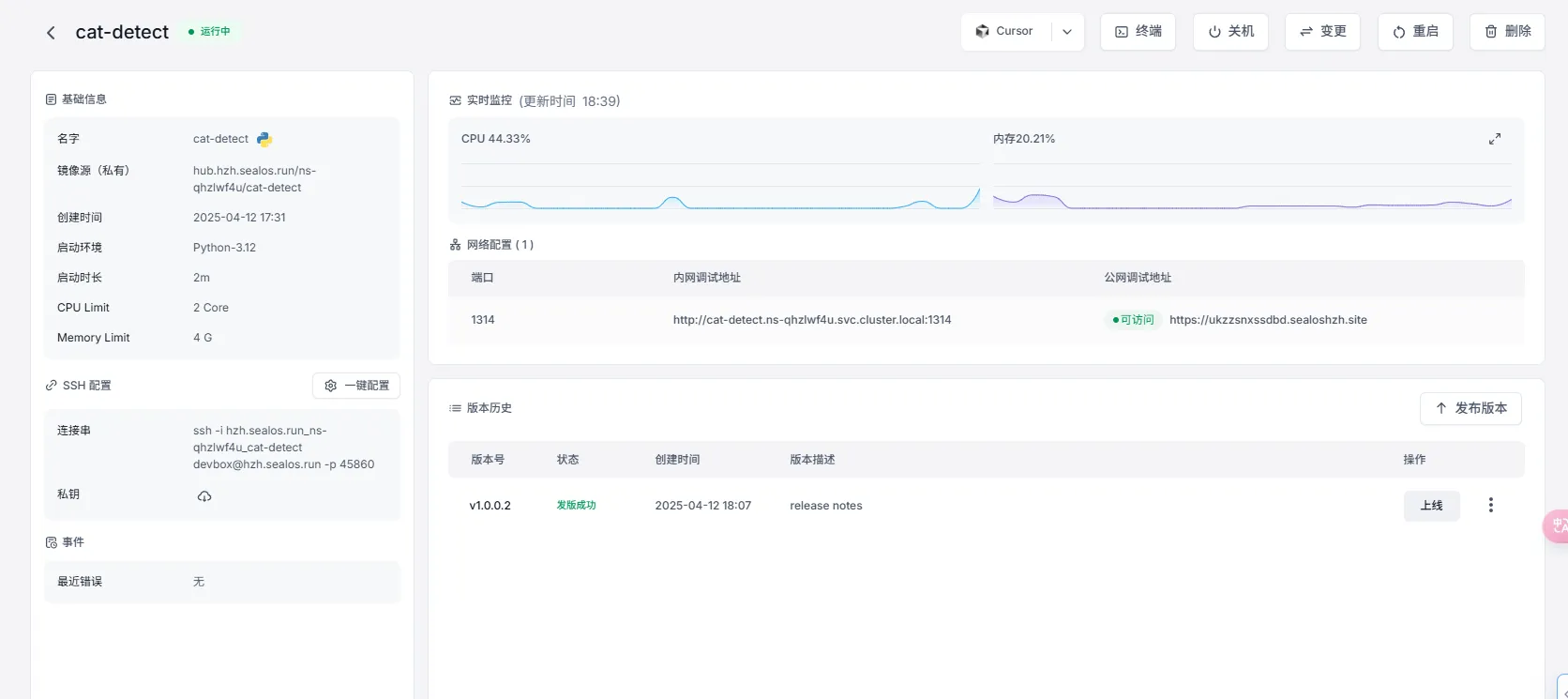
最后修改一下关键信息,部署在 sealos 上即可。
后记
使用预训练其实比较简单,调库,然后塞测试数据就行了。后续可能需要做进一步的数据收集、模型优化和训练。后面的后面或许可以根据别人上传的图片来进行动态训练。
菜啊,有待提升。